Neural Image & Video Compression @Disney Research

Introduction
Most of us are familiar with names like MP3, JPEG, and MPEG. Although we probably know them as file extensions, they are not just that: they are, first and foremost, compression standards 1.
Here, I will try to explain in simple terms the general idea behind compression algorithms, and talk briefly about the research that I conducted with my colleagues at Disney Research.
What is Compression?
Let's imagine that your friend Sarah would like to try your famous homemade vegan chocolate cake. If you want to make sure that she tries the best possible version of the cake, it's straightforward: you bake the cake yourself, carry the cake by hand to her house (walking, since you don't have a car), and deliver it to her. This works, but it is also quite inefficient: The cake is heavy and it takes time to bring it to Sara's place, especially if you walk through busy streets.
If you are not willing to compromise on the quality of the cake, it's hard to get something much more efficient than this. But, even under these circumstances, there are still ways to make the cake a bit lighter and therefore easier to carry. One idea is to give Sarah the cake without any of the heavy store-bought toppings like the chocolate chips and message her a list of the toppings through Signal, including the correct brands and amounts, and with exact indications on when and where to place them on the cake. The catch is that this requires a bit of extra work on both sides: you need to write all of these details, and Sarah needs to do the shopping. But with less weight you can walk much faster and save time overall.
But if all of this still sounds too tiring, why don't you simply write down all the steps required to bake your cake (aka, the recipe) and send it to Sarah? A recipe only occupies a few Megabytes of space, thus it is much faster to send. But, of course, although this is a great idea, there is no free lunch (or cake?): Now you need to accept that the end result won't be exactly like yours, especially if Sarah does not bake as well as you. But if your goal is to save some time (actually, a lot!), it's completely worth it. Besides, if you receive 50 other cake requests, forwarding a message with a few Megabytes is a much better strategy than baking 50 other cakes.
Now, we already found a good solution, but let us introduce a final idea.
Suppose that Sarah and 50 other friends
all ask you for the recipe at a party (because why not?).
As you are happy to share your recipe with everyone who asks for it,
you promise them that you'll write it down in a message later on and send
it to each of them individually through Signal (you haven't discovered group chats yet).
But there is a slight problem: you realize that you only have 30 MB left on your internet budget,
so you need to save as much as space as you can!
An idea to overcome this challenge is to take advantage of the fact that, at that moment, you can
share some information with each other; for example, you can agree that “One tablespoon” will
be written as “1 Tbsp”, “half teaspoon” as “1/2 tsp”, “1 pack of oatmilk
from Oatly” as
“1 milk” (no, I don't receive any money from them 😄), etc.
This allows you to shorten the size of your recipe and fall within your internet plan.
Back to Science
I will now frame this analogy in the language of compression. The idea here is that you're the encoder—you encode the cake into a compressed message—, and Sarah is the decoder—she takes the compressed message and attempts her best reconstruction of the cake from it.
In the first version, the cake was not compressed at all. Sending the complete cake gave you guarantees of pristine quality, but also required a lot of time. Sending uncompressed content over the internet is usually prohibitive: If you could request an uncompressed film from Disney Plus 2 at 4K resolution, they would have to send you the RGB values of each of the 8,294,400 pixels of each of the 130,000 frames of the film, which gives you a total of 3.43 Terabytes of information to download! Just like our car roads, internet “roads” do not have unlimited space (bandwidth) and can get quite congested, so you'd certainly have to wait ⏱ for a good while before being able to watch the film.
In the second version, you were able to carry a lighter cake at the small expense of a Signal message with the list of toppings. This required some additional work on both sides, but because the time needed to carry the cake from your place to hers was so much reduced, you saved time overall. Here, the compressed message was the cake without toppings plus the list; from these two components, Sarah was able to perfectly reconstruct the cake, provided that she followed the instructions correctly. Because you were able to save space without loosing any quality, you performed lossless compression.
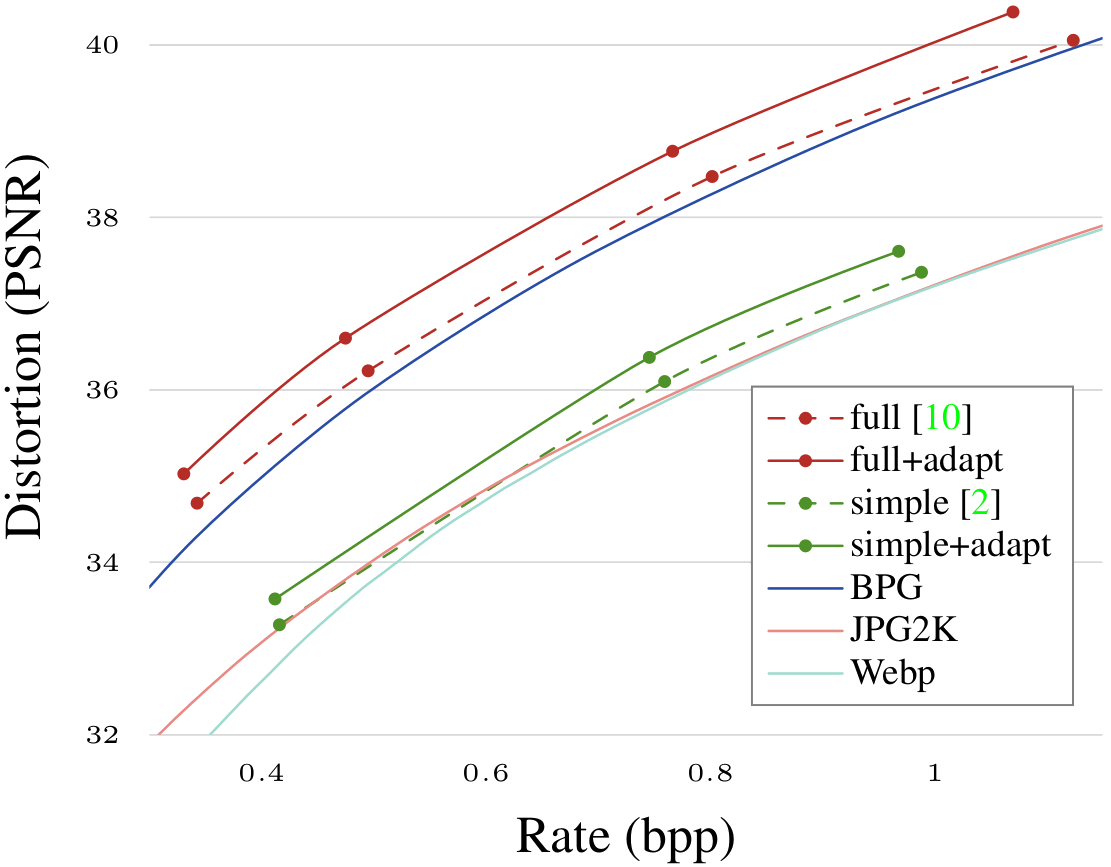
Lossless compression can only go up to a certain point, though. The alternative is to allow some loss of quality for the sake of saving a space and reducing transmission time. This is called as (you guessed it...) lossy compression. The final quality of the cake will depend on how well you can summarize the recipe and how well Sarah can reconstruct it. One crucial point here is to strike a balance between the space occupied—which impacts the transmission time—and the reconstruction quality: if, on the one hand, your recipe is very detailed, it will be very long and take a lot of time to send; if, on the other hand, you summarize your recipe in very few steps, you'll be able to send it faster but the quality of the end result will suffer. For example, a film at 8K resolution will have almost-perfect quality but be quite heavy, and the same film at 240p will download almost instantly, but its quality will be very low. This fundamental trade-off is called the Rate-Distortion curve (you can see one such curve on the top-left image on top): It tells us that if you wish to write down your chocolate cake recipe in two lines, you can, but don't except your friend to come up with anything similar to your homemade cake. A good way to compare compression algorithm is by comparing the reconstruction quality for the same recipe length (as in the aforementioned image).
As is clear by now, a downside of compression is that it requires a bit of “local” work from both the encoder and the decoder. It is fair to ask whether local processing time might not become comparable to transmission time. Since the point of compression is to save time overall, this is intendedly not the case; in fact, most often, encoding and decoding times are negligible compared to the transmission speed, so the latter is the real bottleneck. But it's important to mention that, although low processing time is a definite requirement for the decoder, it is not so much so for the encoder, because the latter only needs to do the job of creating each recipe once, and it can do this before any requests are made. Once a recipe is created, it can be stored somewhere so that, when it is requested, it can be copied and forwarded to the receiver. (For example, Disney Plus is not encoding films into “recipes” every time you click on a film— they just send you the “recipe” that is already stored in their servers.)
The last scenario above is just a way of depicting the way encoders and decoders work in relation to each other: if the encoder performs an operation (e.g., replacing “One tablespoon” with “1 Tbsp”), the decoder will have to do the inverse (e.g. replacing “1 Tbsp” with “One tablespoon”). Roughly speaking, decoders mirror the operations of encoders.
Video Compression
Here, I will briefly explain how compression can be applied to video.
Videos are a sequence of frames (pictures). Since, there are usually 24 or 30 frames per second (fps), the visual differences between frames are usually very small 3 (an exception is when there is scene cut). So if we consider, for example, a 2-second static scene of a landscape, a simple way to compress is to encode the first frame in the scene and then send a small piece of information to the receiver that says “The next 47 frames are the same”. Another very simple way to perform lossy compression of a video is to just drop 1 out of 3 frames, and send a piece of info to the receiver that says “repeat each of these frames 3 times”. This gives you a stop motion film, which is often used in animation for aesthetic purposes. Because close frames are so correlated, and our brains can fill in the blanks, doing so still gives you a fairly good—but not seamless—viewing experience.
Of course, the way actual video codecs work is much more sophisticated. One technique that is used by all video codecs is motion compensation. The idea here is to encode key frames in a film, called intra-frames, on their own (i.e., without using the information of any other frames), and then just encode the differences in motion of other frames relative to the intra-frames. After reconstructing the intra-frames on their own, the decoder can then reconstruct the remaining frames by “adding” their motion information to the intra-frames. In this way, if an intra-frame is encoded at the beggining of an almost-static scene, very little information is needed to reconstruct the following frames because very little motion is present 4.
The Projects, Explained
Now, we're ready to dive into my projects on image and video compression. For this simple explanation, I will continue using the cake analogy. Both works are variations of neural end-to-end compression algorithms, so we'll start with that.
Neural End-to-End Compression
Neural end-to-end compression can be likened to you and Sarah going on a cooking retreat together; during that time, you take a selection of cakes, write down the recipes, and Sarah tries to bake them. As the retreat progresses, you both improve your skills over time by learning jointly from your mistakes, that is, by comparing the original cake with Sarah's version and offsetting the differences. You gradually improve your recipe-writing skills, and Sarah her recipe-reading-and-interpreting and baking skills. This process is neural/AI-driven because the encoder and decoder learn from the data, and it is end-to-end because it works solely by comparing the input (your cake) with the output (Sarah's cake), with no other mechanism at play.
(Now, get ready for some Sci-Fi...)
After the retreat, both you and Sarah upload your minds into a cyborg and switch off the cyborgs' training mode: your cyborg cannot improve its recipe-writing skills and Sarah's cannot improve its reconstruction skills. (Just like ChatGTP—apparently, humanity's cyborg 😅—has its training mode switched off since its creation in 2021.) Once you are back home and you have another cake to send (one that you haven't necessarily experimented with during the retreat), you ask your cyborg to write down the recipe and send it to Sarah, and she asks her cyborg to bake the cake from it. Having trained together for two weeks, the results will be much more satisfying than if you had not.
Notice that now we have separated the sender (you) from the encoder (your cyborg), and the receiver (Sarah) from the decoder (her cyborg). (In streaming terms, the sender might be Disney Plus, the encoder a piece of software in their servers, the decoder a piece of software in your laptop, and the receiver you—the end user.) These distinctions are important to explain that both the sender and the receiver can have access to the encoder and decoder. In terms of our analogy, this means that both you and Sarah can have a clone of each other's cyborg at your respective places (apart from your own cyborgs).
The First Project: Content-Adaptive Neural Image Compression
We're at the point where both of your cyborgs have finished their training together and you have a new cake to send. For this algorithm, it is necessary that apart from your own cyborg, you also have a clone of Sarah's cyborg at your place. Assume this to be the case.
Let's consider why it is, in the case of the decoder, mandatory, and in the case of the encoder, a good idea to switch the cyborgs' learning modes off.
First, the decoding cyborg that is at Sarah's place does not know which cake actually originated the recipe (that's its job to guess), so it cannot use the differences to improve itself—unlike when you were both training together in your cooking retreat. Hence, the decoder (both hers and the clone that you have) needs to be fixed.
What about your own cyborg? Your cyborg does have access to both the original cake and to the end result because you have a copy of Sarah's decoding cyborg that can bake the cake exactly like hers. So, in theory, you could leave your cyborg's training mode on and run the process of recipe-writing-and-baking a few times for each new cake so that your cyborg can adjust itself to create a better recipe for that specific cake. This would make the compression content-adaptive (or cake-adaptive). The problem with this approach is that it does not give you reliably good results. It might well be the case that if you start tweaking your cyborg to improve the reconstruction quality for a specific cake, it will worsen it for other cakes, because of over-tweaking (aka overfitting). Moreover, if you give your still-in-training cyborg the same recipe at different times, it will give you different results and one of them might be much worse than if you had decided to switch off its learning mode after the cooking retreat. (Imagine that, at some point, you download a film on Disney Plus with good quality, and a month later the quality is much worse with the same exact bandwidth...)
What if there was a way to magically tweak the recipe itself without having to modify neither the encoder nor the decoder while mantaining the length of the recipe (so that the transmission time is not increased) and having the assurance that the quality of the end result will be, at best, much better, and, at worst, the same?
This is precisely what we did in this project. The sender (you) can run the process of recipe-writing-and-baking a few times for each new cake and simply tweak the recipe (which is now a little learning cyborg itself), without modifying the encoder and decoding cyborgs. Because the recipe is much less complicated than the cyborgs, it is much faster to update, and because it occupies very little space, you can save the original recipe after the first encoding just in case the tweaked one does not give you better results. The downside is that this takes extra work and time on the sender side. However, if what matters is the time required to send the recipe when it is requested and not as much the time that it takes to write it down, it's worth it! As mentioned previously, this is usually the case: for example, when Disney Plus decides to launch a new film, it doesn't really matter if they take an hour more to compress it than usual if the end-quality is improved, as long as the time it takes to send it when users ask for it is not increased. Again, the recipe only needs to be created once; after that, it can then be copied and forwarded as much as necessary.
The top-left image on top shows how our content-adaptive image compression method compares to modern image codecs like BPG and WebP, and to the baseline neural compression algorithm without adaption.
The Second Project: Neural Inter-Frame Video Compression
This project incorporates many different ideas. Here, I will only give the general picture and explain the concept of latent-space residual encoding (don't mind this). For this algorithm, Sarah also needs a clone of your cyborg at her place, so that both you and Sarah have access to the encoder and the decoder. Assume this to be the case. Now, the process is a bit more convoluted, but let's see it carefully.
This is what you, the sender, needs to do to create the compressed message for a new cake: First, you ask your cyborg to write down the recipe for the cake. Second, you ask your version of Sarah's cyborg to bake its flawed version of the cake from that recipe. Third, you make a second request to your cyborg, asking it to write down the recipe for the cake Sarah's cyborg just baked. (Just follow me here 😅.) Ok, so now you have two recipes: the original one and the one for Sarah's flawed cake. The last thing you need to do is to check the differences between the two recipes and write down an errata (i.e., a side recipe) to correct for the mistakes. Finally, you can send a compressed message to Sarah which consists of the original recipe together with the errata.
Now, this is what Sarah, the receiver, needs to do to reconstruct the cake from the original recipe and the errata: First, she asks her cyborg to bake the cake from the recipe. Second, she asks her version of your cyborg to write down the recipe from the flawed cake that your cyborg just baked. (These two steps are the same as your 2nd and 3rd steps). Third, she takes the most recent recipe, reads the errata and uses it to correct the new recipe, thus generating a corrected version of the recipe. Finally, she asks her cyborg to bake the final cake from the corrected recipe.
That's it! Thank you for reading this far.
The top-right image on top shows how our video compression method compares with standard codecs such as HEVC/H.256.
Publications
Patents
Impact
We achieved state-of-the-art results at the time of publication with both works, and together they led to the registration of three US patents [1, 2, 3]. The work on video compression has been cited over 150 times, including in publications from Nvidia, Google [1, 2], and Microsoft. The work on image compression has been cited over 40 times, including in publications from Google, University of Oxford, UC Irvine, Qualcomm, Uber, Microsoft, Nokia [1, 2], and Huawei.
Tech Stack
Here I outline a few technologies that I used in these projects.
- Python: Programming language.
- Pytorch: Deep learning framework.
- Bash: Unix shell and command language.
Acknowledgments
I would like to thank my Disney supervisors, Aziz Aziznejad and Christopher Schroers, and my Disney colleagues Simon Meierhans (who gave the original idea for the first project), Pierre, and Natalie.
Footnotes
[1] More sophisticated standards have since taken the place of these older ones. Some examples in video (which are based on MPEG) are H.265/HEVC, VP9, and AV1. The latter is used by Netflix.
[2] I am using Disney Plus for the streaming examples because these projects are the result of joint work with my colleagues at Disney—whom I love—and I also don't want to get into legal trouble 😅.
[3] We say that there is a lot of redundancy in the signal.
[4] Motion information has a much lower entropy than full frames, which means it is much easier to compress.